Praca Magisterska
Celem mojej pracy magisterskiej jest porównanie wydajności czterech różnych modeli detekcji obiektów w obrazach: YOLOv7, RetinaNet oraz Mask R-CNN z wykorzystaniem MMDetection, w zakresie analizy i detekcji obiektów na zdjęciach.
W pracy magisterskiej porównano trzy popularne modele detekcji obiektów w obrazach: YOLOv7, RetinaNet oraz Mask R-CNN, implementowane przy użyciu frameworka MMDetection. Każdy z tych modeli reprezentuje inne podejście do detekcji - YOLOv7 to bardzo szybki i dokładny model jednokrokowy, RetinaNet wykorzystuje sieć piramid cech (FPN) oraz funkcję strat Focal Loss, co pozwala mu skutecznie wykrywać także małe obiekty, natomiast Mask R-CNN, jako model dwustopniowy, umożliwia nie tylko wykrywanie obiektów, ale również segmentację instancji, czyli wyodrębnianie ich kształtu na poziomie pikseli.
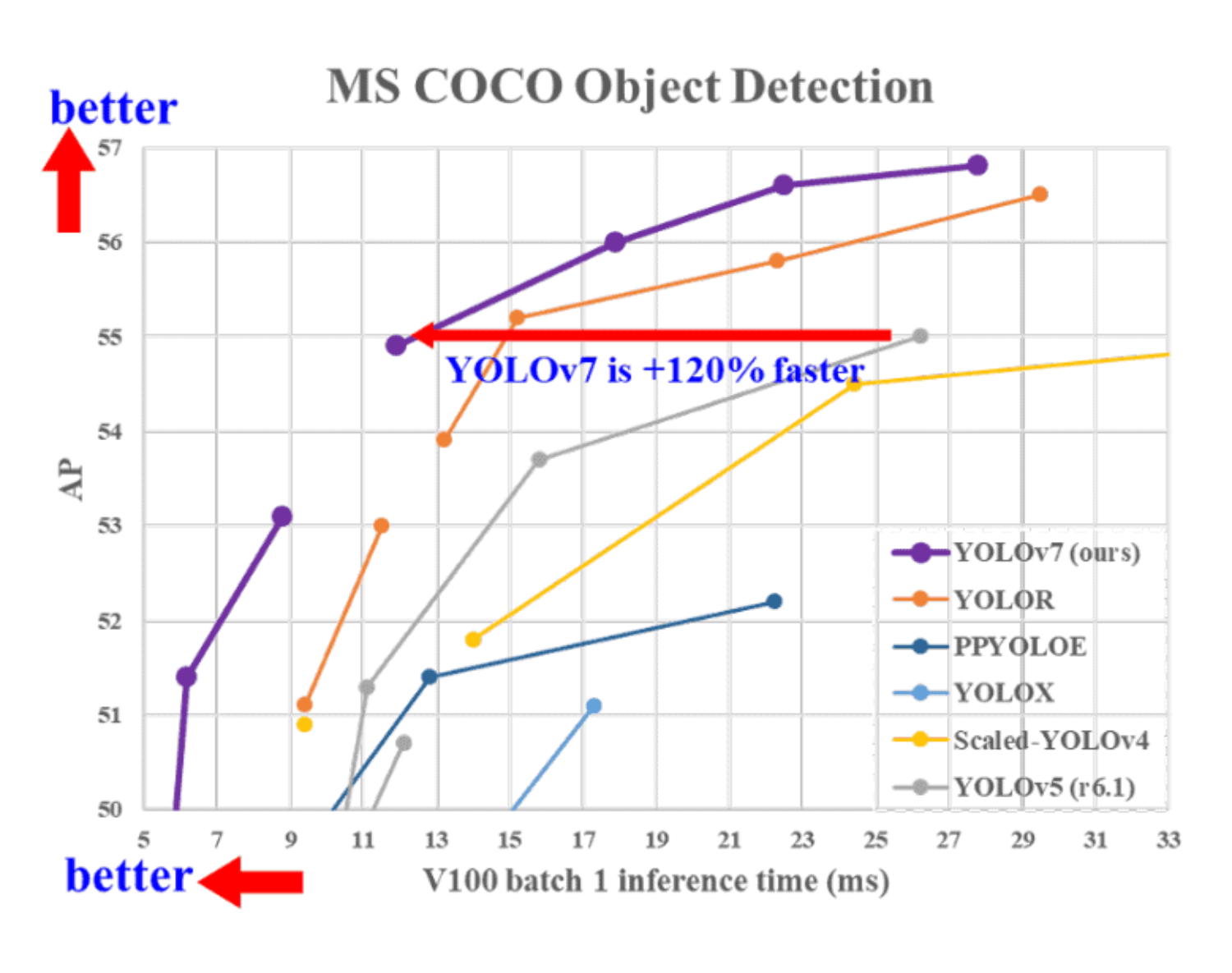
Do przeprowadzenia badań wykorzystano zestaw danych COCO (Common Objects in Context), który zawiera ponad 330 tysięcy zdjęć przedstawiających obiekty w różnych warunkach i kontekstach. Zbiór ten uchodzi za jeden z najbardziej wymagających benchmarków w dziedzinie detekcji obiektów, ponieważ obejmuje dużą różnorodność klas, perspektyw, warunków oświetleniowych i tła. Dzięki temu umożliwia kompleksową i rzetelną ocenę działania testowanych modeli w zróżnicowanych scenariuszach.

Wyniki badań pokazały, że wszystkie analizowane modele mają swoje mocne strony i ograniczenia. YOLOv7 wyróżniał się najlepszym kompromisem pomiędzy dokładnością a szybkością, co sprawia, że nadaje się do systemów czasu rzeczywistego. RetinaNet osiągał bardzo dobre rezultaty w detekcji małych i licznych obiektów, natomiast Mask R-CNN, choć wolniejszy, oferował najwyższą precyzję w segmentacji instancji. Podsumowując, wybór modelu zależy od specyfiki zastosowania - od wymagań dotyczących szybkości po potrzebę bardzo dokładnej analizy obrazu.
